This post focuses on cryptography in groups. We will talk more about how to securely exchange information over public channels, and how to ensure security in the key exchange protocol. We will also take a look at which mathematical issues we face and which methods to use for solving them.
Let’s get to the point. Sharing a message and retaining its secrecy seems, at first, like quite a hassle – to create a secure channel for message delivery, we need a secure channel for key exchange. Fortunately, it’s all not bad. The solution of this paradox lies in the word secure, which is currently being used in two different meanings. The security of the message channel means, first and foremost, the secrecy of the message. But it turns out that we don’t necessarily need secrecy when it comes to the key exchange channel. It’s enough when that channel is authentic, i.e. the communicating parties can somehow be sure that their partner is really who he claims to be. Assuring authenticity is not a simple task, even for communication sessions rolling out on the Internet, but authenticating another party (maybe even a stranger) is, in principle, possible. We are not going to concentrate on this issue here, though, and will from now on assume that we have an authentic, but possibly non-private, channel.
A principal solution, how to exchange a key over a channel potentially vulnerable to eavesdropping, was offered by Martin Hellman and Whitfield Diffie in 19761. Their idea was to use the multiplicative group of finite prime order field Z*p. Let’s choose a generator g for that cyclic group and forward it publicly to the parties interested in agreeing on a common key. In cryptographic tradition, these parties are called Alice and Bob.
The next step for Alice and Bob is to each choose a random secret natural number from the range [1, p – 1]. Denote these numbers as a and b, respectively. Alice calculates the value ga in the group Z*p, and sends it to Bob. Bob in turn, sends gb back to Alice. Now, Alice can calculate the value (gb)a and Bob (ga)b. As
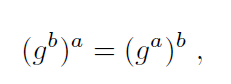
Alice and Bob now have a common element in the group Z*p which has not been shared, even once, over the key exchange channel. This will be their common shared key.
Nevertheless, the attacker can see the values g, ga, and gb over the public channel. The overall security of key exchange protocol depends on how easy or complicated it is to derive the secret gab from them. This task is known as the (computational) Diffie-Hellmann problem. The best known general method for solving it is to first find the power a based on g and ga (basically a logarithm) and then calculate (gb)a.
Exponentiation can be performed relatively efficiently in the residue class field (it will take 2 log2_(p)_ of multiplications the most), but what is the case with the reverse operation? Our experience with real numbers seems to suggest that using the series for logarithm computation cannot be overly complicated. However, the discrete nature of the residue class structure will start playing its part. Zp is not continuous nor dense, which is why we cannot talk about convergence or the series won’t work.
Mathematicians have developed other approaches as well. In general groups, we can use for example Shanks’ baby-step-giant-step algorithm or Pollard’s p-method to calculate the discrete logarithm. The expected operating time of both of these in case of a group of n elements is roughly √_n_ group operations2.
In practice, the prime p values which are a couple of thousand bits long, are used for Diffie-Hellmann key exchange, e.g. p ≈ 22048 or p ≈ 23072. As for
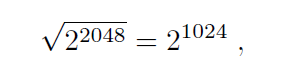
general algorithms for calculating discrete logarithm will not succeed in the case of such values.
At the same time, there are many different structures in the residue class fields, other than the one of an abstract multiplicative group. These structural features can be used to create more effective algorithms.
The best results have been achieved with different sieving techniques, which enable us to bring the (heuristic) complexity of time of calculating discrete logarithms down to two
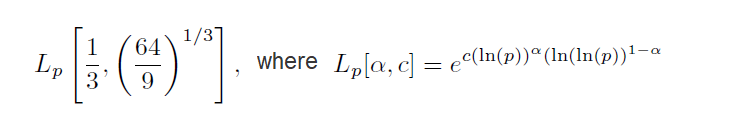 (1)
(1)
(see for example Thomé’s work3). If p ≈ 22048, then
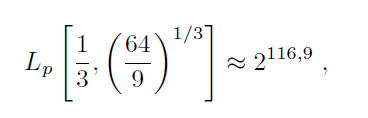
which is far less than 21024, that was found with general methods for calculating discrete logarithms, but will still remain out of reach of the performance limits of present computers.
Actually, the asymptotic complexity of these methods is more important than the difference in calculating specific resource requirements of discrete logarithm computations. According to the tradition used in complexity theory, the time required for running the algorithm (time complexity) is expressed as a function of the length of the input. Also, the growth pattern of the function for increasing values is considered more important than possible constant coefficients in front of the function expression. You can find out yourself that, at some point, each (positive) square function grows past a linear function, a cubic function grows past a square function, an exponential function with base higher than 1 grows past each polynomial, etc.
That is why, for example, if possible, an algorithm with a polynomial time estimate is preferred to an exponential one.
To be correct in estimating the complexity, we must pay attention to determining the length of the input. There are p – 1 elements in a group Z*p, but these elements are usually presented through some kind of positional numeric system, which is why the length of the element is logarithmic with respect to the cardinality of the group. The base of the logarithm depends on the base of the chosen numeric system. Logarithms taken on different bases differ from each other by the constant coefficient, which is why the base of the logarithm is not extremely important while determining the asymptotic class of complexity of an algorithm. So, we can, for example, use a natural logarithm in the following example.
Let’s remind ourselves that in general groups, algorithms used for calculating discrete logarithms require about √_n_ group operations, where n is group order, to work. In case of a group Z*p, we will get
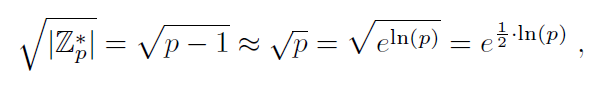
which is exponential with respect to the length of the input ln_(p)_.
Now, let us look at the expression in formula (1). If α = 1, then
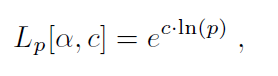
which is also exponential with respect to ln_(p)_. If α = 0, then
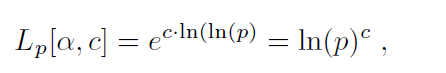
which is polynomial with respect to ln(p).
When changing the value of parameter α from 0 to 1, we will move further away from polynomial, and towards an exponential estimate. Since sieving techniques have achieved algorithms with a parameter α = 1/3, we are dealing with functions with complexity lower than the exponential ones. That is the reason why sieving techniques provide a remarkably lower complexity in case of multiplicative groups of residue class fields.
At the same time, do not forget that, for example, Diffie-Hellman key exchange protocol can be defined in an arbitrary group. Therefore, the question: whether the group chosen as the basis of the protocol could be selected so that the sieving techniques would not work, is justified. It turns out that it can be selected this way and the most common alternative to residue class structure is the group of elliptic curves.
That was a comprehensive explanation about cryptography in groups, and our next post will be covering elliptic curves.
Written by Jan Willemson
1 Whitfield Diffie and Martin E. Hellman. New directions in cryptography. IEEE Trans. Information Theory, 22(6):644–654, 1976.
2 Alfred J. Menezes, Paul C. van Oorschot, and Scott A. Vanstone. Handbook of applied cryptography. CRC press, 1996.
3 Emmanuel Thomé. Algorithms for discrete logarithms in finite fields and elliptic curves, 2015. https://www.math.u-bordeaux.fr/~aenge/ecc2015/documents/thome.pdf.